What is a Database ?
I've always been curious about how things operate. Databases are a key component of modern technologies. Every developer uses databases and is familiar with PostgreSQL, MySQL, and MongoDB, among other types and versions. However, is he truly aware of what a database is? In reality, what is a database? Is it only data storage? and how it accomplishes its goal.
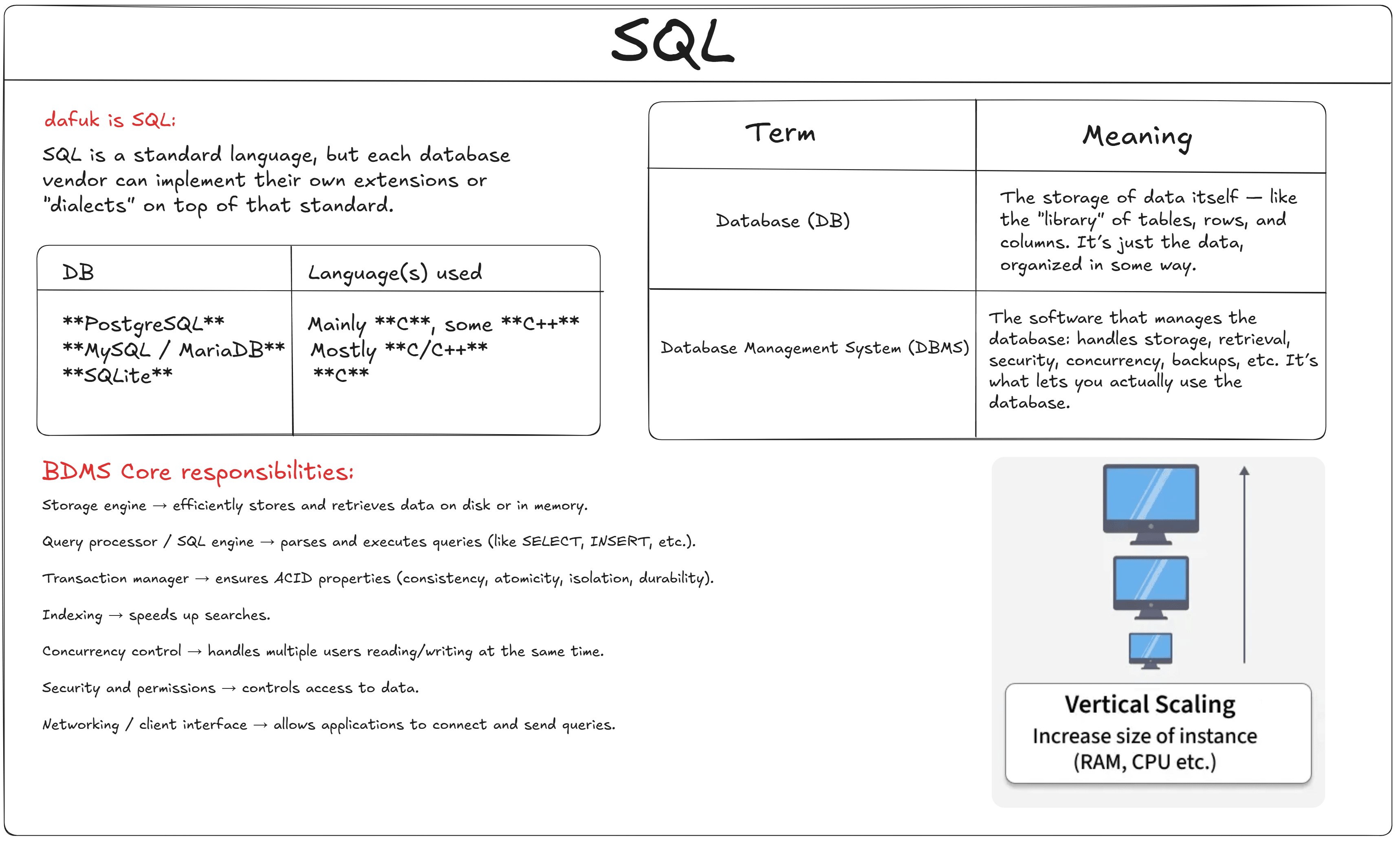
Before we move on to this fascinating topic, let us clarify a few points. A database (DB) is what you create with a database management system (DBMS). To make things easier, I'll start using the terms "DB" and "DBMS."
To develop my own DBMS and address these questions, I immersed myself in the vast field of data management systems.
There are two types of databases: relational databases, which commonly utilize SQL (Structured Query Language), and non-relational or NoSQL databases, which use different data models and query algorithms.
Relational Databases
Relational databases are characterized by the relational model (tables, keys, relations) and are often built using ACID (Atomicity, Consistency, Isolation, Durability) principles. In other words, data is organized in tables with relationships between them. The ACID principle ensures that all transaction steps (multiple interactions with the database) are completed as a single operation or not done at all (Atomicity), and that data moves from one valid state to another (Consistency). The current transaction must not interfere with another (Isolation), and any modifications made must be persistent (Durability).
For example, if I want to send $100 to a buddy, my account will be deducted $100, while my friend will receive $100. This is a transaction; if one of the two operations fails, neither will be completed. I can't go negative on my balance, so both before and after the transaction must be positive, which is the consistency. If my brother buys anything with my bank card at the same moment, his transaction must not interfere with mine; each transaction is isolated. If everything is completed as intended, the changes will be preserved even if the system crashes immediately following the changes.
Structured Query Language
The first thing that we interact with when using relational databases is the Structured Query Language, or SQL, as it is more commonly known. Standardized by ANSI and ISO, SQL is the perfect declarative language used to communicate with relational databases. "STANDARD" obviously implies that SQL must be the same across all databases that use it. While many SQL databases have similar features, there are notable exceptions. The syntax differences are illustrated in the following example.
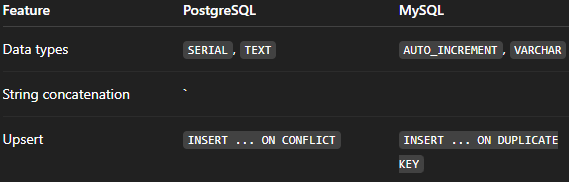
Yes, SQL is a standard language, but each database vendor can implement their own extensions or “dialects” on top of that standard, and that's what makes these slight differences.
How? The query processor plays a crucial role; it is a DBMS core module that takes a high-level query (like SQL) and turns it into an efficient execution plan that the underlying database engine can run.
A DBMS's primary function is to store data, so it is natural that a storage engine is required; it abstracts the physical data layer from the logical levels of the server and offers the server's low-level input/output (I/O) functions. Moreover, it must allow fast reading and writing, manage indexes, and support transactions and ACID principles, ensuring the integrity of the data and the recovery of crashes.
In conclusion, relational transactional databases are an effective approach with a solid and straightforward structure. But, if such databases and BDMSs are so good, why are there several types of databases and DBMSs? What are their limitations, and what was the tipping point that prompted us to develop new database models?
Limitation
What makes relational databases so powerful is also their weakness: relationships. The problem is that it's harder to scale them horizontally (by adding more server instances). Placing related data in separate locations can be problematic. When attempting to access this data, we encounter the issue of joins across nodes: how can we filter data based on information that isn't available on this server? And accessing the missing information leads to increased latency and higher bandwidth usage. Additionally, when inserting or updating, we encounter the problem of constraint enforcement and indexes. Furthermore, due to the nature of these databases, unstructured or semi-structured data is difficult to manage. And that's what takes us to NoSQL.
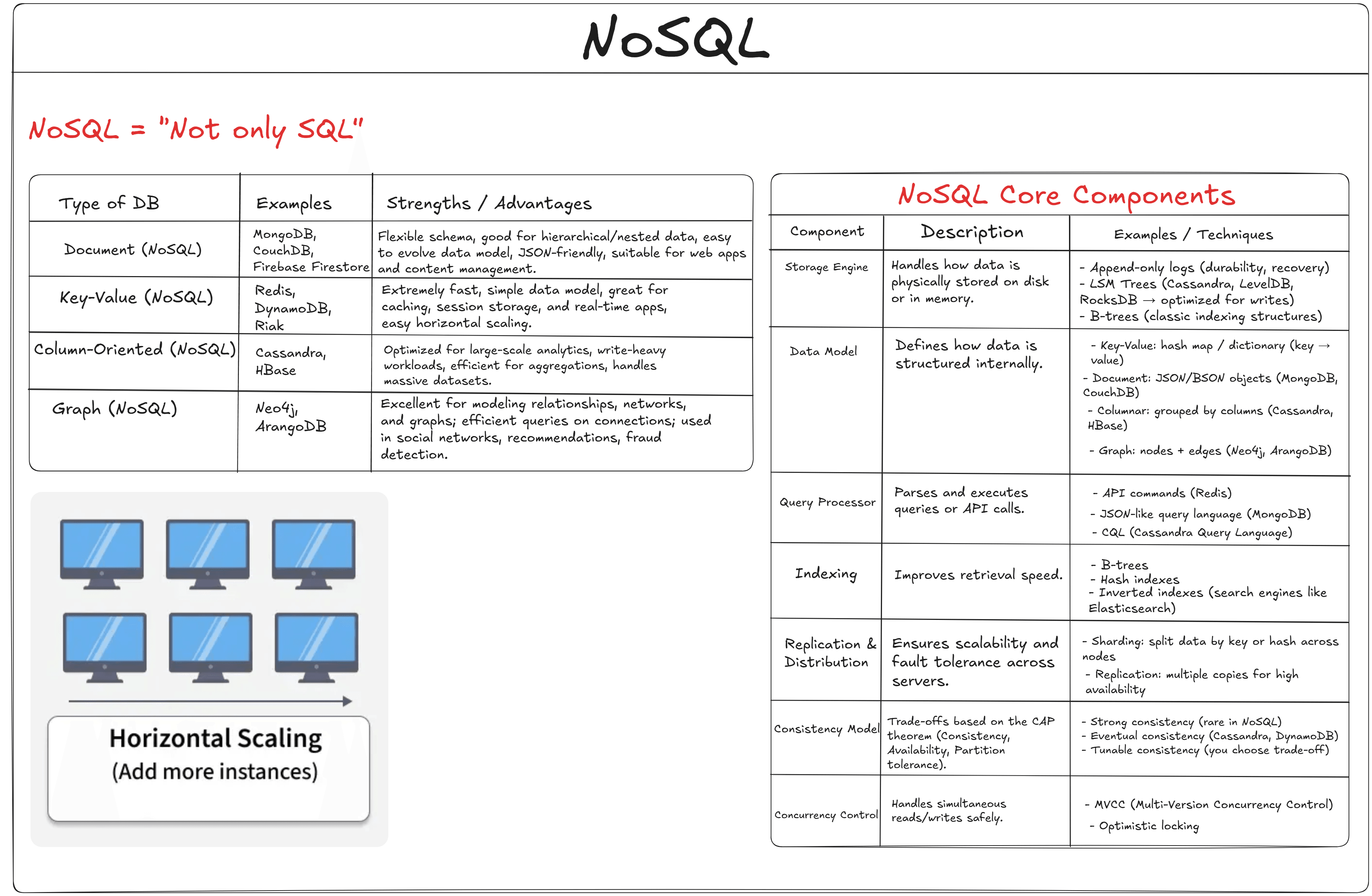
NoSQL
NoSQL (Not Only SQL) is a vast family of different databases: document-oriented, key-value, column-oriented, and much more. Each of these types of systems has its weaknesses and strengths. Every type of these databases solves one or multiple issues mentioned earlier, of course with their own tradeoffs. For example, document-oriented databases like MongoDB provide a flexible schema, solid support for hierarchical and nested data, and utilize a JSON-friendly data structure, making them suitable solutions for web applications and content management. Key-value DBs are extremely fast and great for caching, session storing, and real-time apps. Easily scaled horizontally, they are now a widely used solution in many fields.
Still, they're not the perfect solution. Many NoSQL systems relax ACID guarantees in favor of the trade-offs described by the CAP theorem (Consistency, Availability, Partition tolerance). While this design enables high scalability and fault tolerance, it can limit transactional reliability and query complexity compared to relational systems. NoSQL systems are powerful tools for specific scenarios, but they are not a one-size-fits-all solution.